|
Hi! I am an Master's graduate in Electrical Engineering and Computer Science from University of Michigan Ann Arbor, where I specialized in Signal, Image Processing, and Machine Learning. I am passionate about leveraging cutting-edge technology to create a meaningful and positive impact on the world. I obtained my undergraduate degree in Electronics and Communication Engineering, complemented by a minor in Computer Science, from PES University in 2020. My educational background, combined with my courses at the University of Michigan, have helped me develop a strong foundation in computer vision and machine learning. If you have a similar passion for technology and innovation, I'd love to connect with you. Whether we explore potential research collaborations or simply engage in insightful conversations about the latest advancements in our field, feel free to get in touch with me. Feel free to say hi at : kemmannu at umich dot edu |

|
|
|
|
I'm broadly interested in intersection Computer Vision, Deep Learning and NLP. I am particularly interested in exploring self-supervised representational learning methods, utilizing multi-modal pretraining, especially language supervised pretraining, to address challenging vision tasks such as classification and detection. Developing a novel training recipe for open vocabulary instance segmentation without the need for aligned data, inspired by the distinct ”what” and ”where” pathways observed in the human visual system (working towards submission for ICLR 2024) |
|
Sunnyvale, CA , Manager:Prasad Shamain Conducted research, collaboration, and implementation of a privacy-focused Deep Learning solution for a complex problem involving radar inputs for a specific Amazon product Designed and implemented a Computer Vision Ground Truth system, Data-Collection pipeline, and synchronization, while exploring different deep learning methods for a Radar Based System, considering resource constraints and providing key insights for decision-making |
|
Here are some of the projects that I have been working on :-) |
|
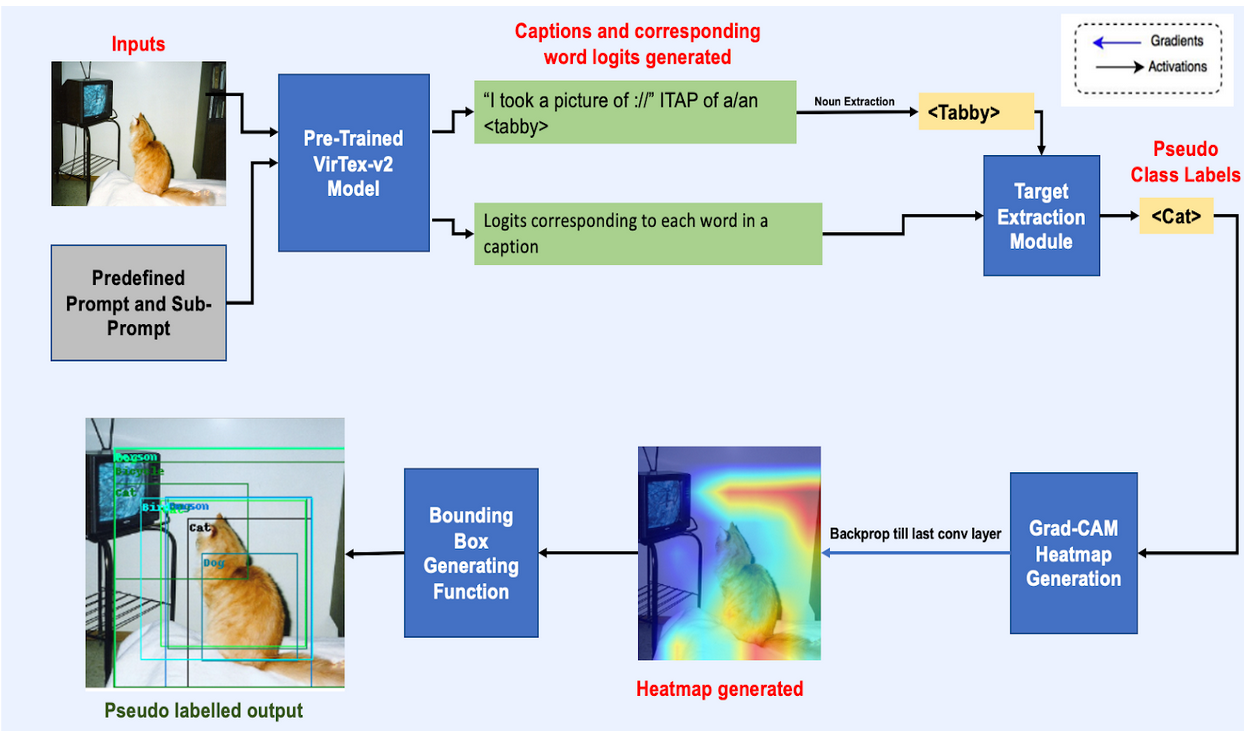
EECS 545 Course Project , Supervisor :Honglak Lee Report / Poster Our novel proposed method drastically reduces the need for human supervision required for training an Object Detector. We leveraged a language supervised pre-trained bi-directional captioning model (VirTex-v2) that outputs a set of diverse captions given an image. Further, we performed zero-shot transfer using prompt engineering and then filtered the results using noun and target extraction modules to obtain a set of "words of interest" from the generated captions. With these "words of interest," we utilized Gradient Class Activation Maps to localize an object within an image and draw a bounding box around it. This created pseudo labels and pseudo bounding boxes that acted as supervision to train the Object Detector. Finally, we trained a Fully Convolution Single Stage Object Detector (FCOS) using a new small modified version of GioU loss to account for the noise in the generated pseudo bounding boxes. Our techniques were verified on the Pascal-VOC dataset. |
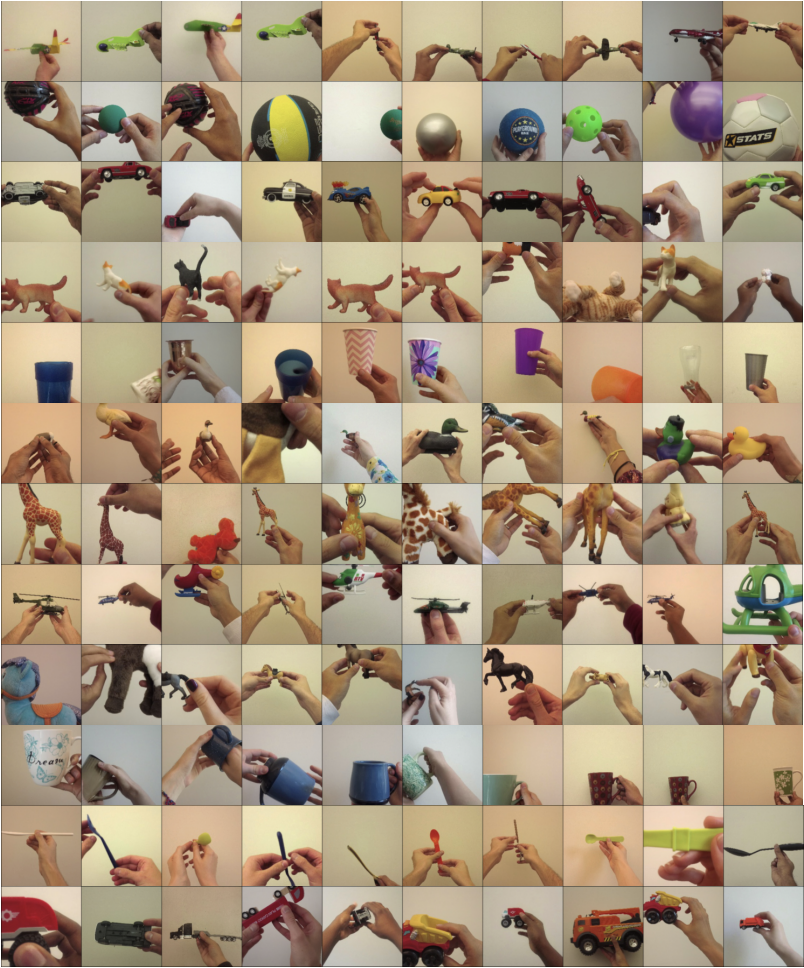
|
EECS 598 : Action and Perception Course Project , Supervisor :Dr. Stella Yu Report This course project focused on the exploration of data diversity versus view diversity in representation learning using the novel approach named ToddlerNet. Inspired by physological concepts by Dr. Linda Smith, we aimed to leverage insights from infant perception research to enhance deep learning models. Our investigation primarily centered on understanding the significance of data statistics resembling infants' everyday environment in improving object recognition across different contexts and viewpoints. ToddlerNet demonstrated promising results by training algorithms on data exhibiting infants' perceptual experiences, leading to a more robust recognition of objects under various viewing conditions. Additionally, we explored optimal learning objectives and discovered that pre-training with a supervised contrastive learning objective on view-diverse data yielded superior results in ToddlerNet's performance. This finding showcases the potential of leveraging view diversity in representation learning for enhanced object recognition capabilities. |
|
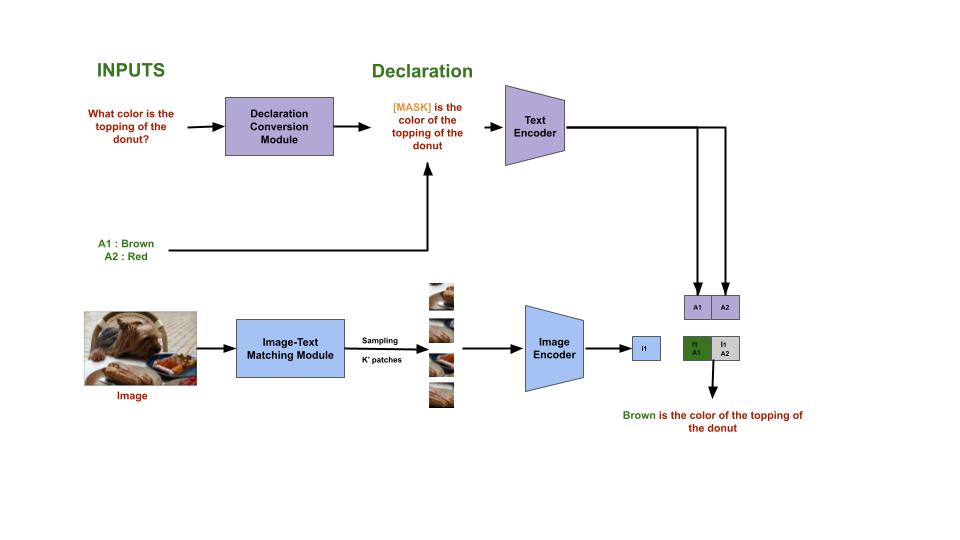
EECS 595 Course Project , Supervisor :Prof. Joyce Chai Report In this course project, we developed a novel pipeline to perform zero-shot Visual Question Answering (VQA) by combining large pre-trained models, such as CLIP and the T-5 transformer. Our approach involved converting questions into declarative statements and leveraging them alongside images and multiple-choice answers to perform zero-shot VQA using CLIP. Our pipeline achieved an impressive total accuracy of 49.5%, which is comparable to the state-of-the-art (SOTA) performance in zero-shot VQA and outperformed the previous SOTA in this task. This success demonstrates the effectiveness of our customized prompts and the potential of large pre-trained models for zero-shot VQA. |

|
EECS 598 Course Mini-Project , Supervisor :Justin Johnson Report For this research project, we compiled a unique and curated dataset, referred to as "SubRedCaps," consisting of image-caption pairs extracted from sub-reddits specifically related to food. The dataset spans the time period from April 2020 to April 2022. To enable our study of food image captioning, we pre-trained a bi-directional image captioning model using RegNeX-800MF as the feature extractor for the images. Additionally, we utilized a two-layer encoder-decoder transformer architecture to learn rich semantic representations from the captions, leveraging our subsampled SubRedCaps dataset. Despite working with limited hardware resources, our best model achieved a remarkable 20% zero-shot accuracy on the test-set of the challenging Food-101 dataset. This noteworthy result demonstrates the efficacy of our approach in generating accurate captions for food-related images. |
|
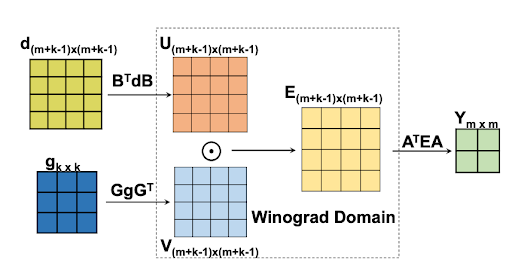
EECS 598 Course Project , Supervisor :Hun-Seok Kim Report We designed and developed an 8-bit quantized flexible Winograd-based convolutional engine in Verilog to achieve decreased inference time and model size for Convolutional Neural Networks (CNNs). To validate the design, we conducted simulations of the entire inference cycle of a CNN using MATLAB. Our investigation primarily focused on exploring and implementing various quantization techniques widely used in tinyML (Tiny Machine Learning) to effectively reduce model complexity while preserving accuracy. |